
Technical Dive: Shadowing factory contracts


Shadow unlocks deeper data access by allowing anyone to edit a deployed contract's source code to emit shadow events, which are executed in an offchain simulation environment called a shadow fork. Developers and analysts can get deeper data coverage by enriching existing contracts to generate these net-new events.
We recently added native support for shadowing factory contracts to the Shadow platform. With factory support, you are able to make one set of changes to a factory contract, and propagate those changes across all of the child contracts it has ever deployed.
For example, this allows you to make one set of changes to the Uniswap V2 pool factory contract, and have those changes apply to all 300K+ Uniswap V2 pools, instead of shadowing each one individually – a tedious and impractical process.
Building native support for shadowing factory contracts presented some interesting technical challenges. In this post, we’ll dive into these challenges and how we solved them – highlighting key details about the EVM and shadow execution.
What are factory contracts?
A factory is a contract that can deploy multiple instances of the same contract — we call these child contracts.
Generally, child contracts share the same functionality, but are typically initialized with different constructor arguments, which may alter the child contract’s runtime bytecode. Factory contracts are widely used across many protocols, including Uniswap, Compound, and Pendle.
How do contract deployments work?
Before we get into the technical challenges of shadowing factory contracts, let’s first cover important details about how factory contract deployments work within the EVM.
Here’s what that happens when a contract is deployed (simplified):
- The EVM determines the address of the contract
- The EVM generates the bytecode of the contract
- The EVM stores the bytecode of the contract at it’s address
The contract’s state also gets initialized at the time of deployment, but we won’t be covering those details in this blog post.
How is the contract address determined?
A factory contract computes the address of a contract upon deployment via the CREATE or CREATE2 opcodes. The main difference between CREATE and CREATE2 is how the address is calculated.
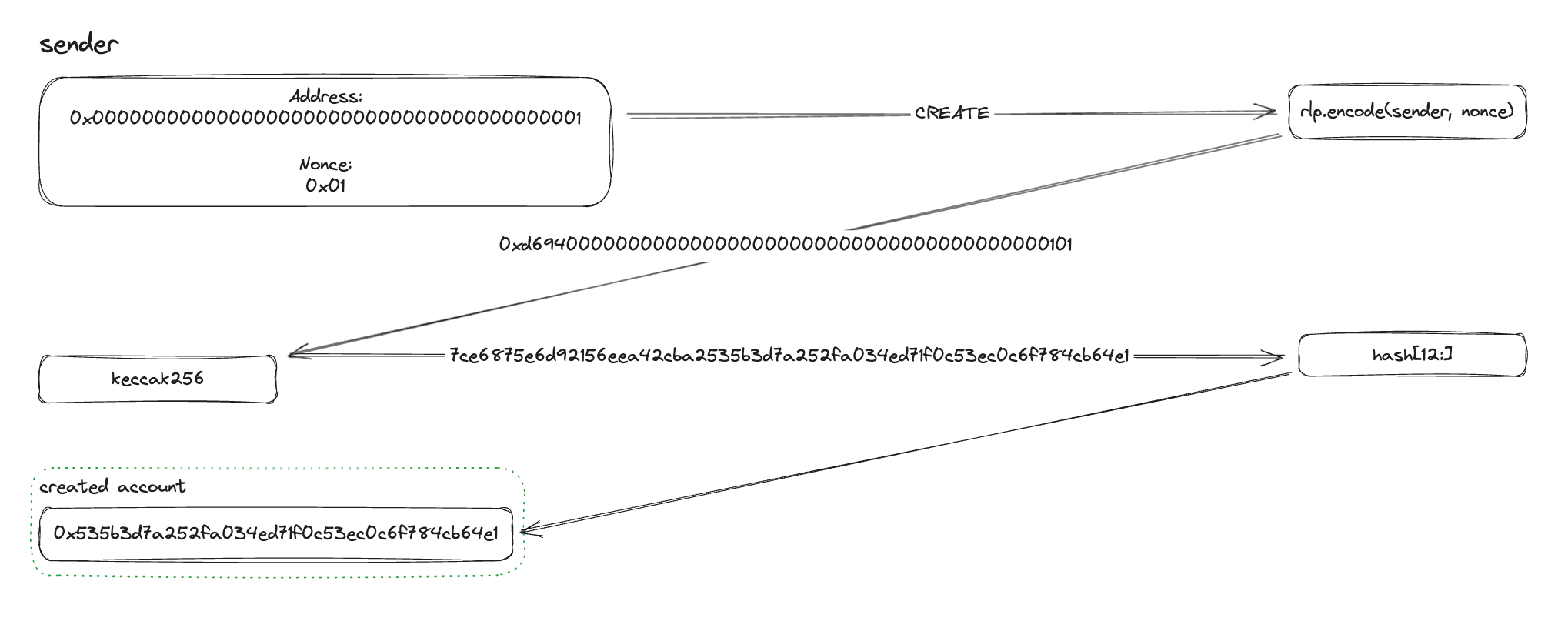
The CREATE opcode calculates the address using the msg.sender and the sender’s nonce. For factory deployed contracts, the msg.sender will be the factory contract, and the nonce will increase every time the factory creates a new child contract.

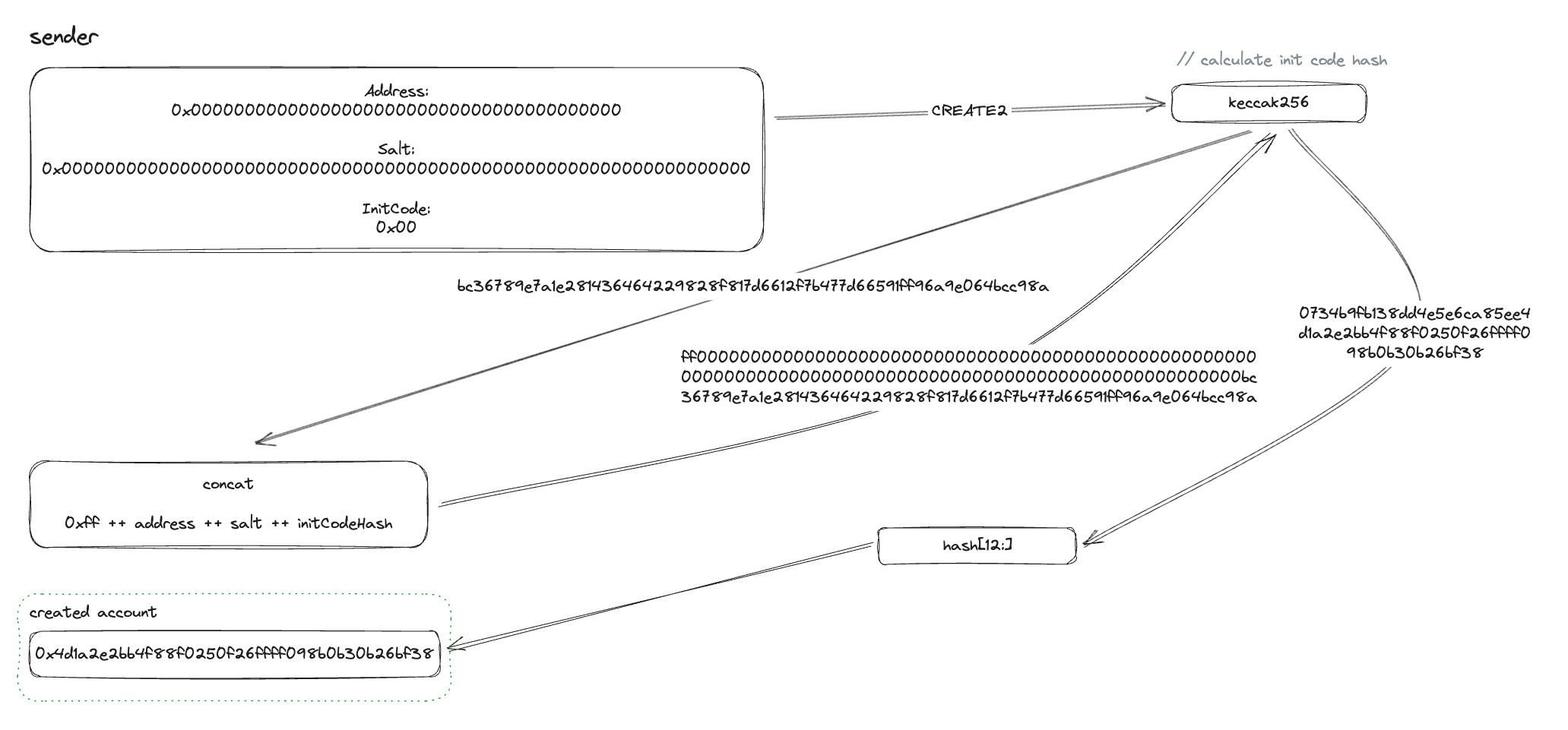
The CREATE2 opcode determines the address using the msg.sender, a salt, and the init code of the contract. CREATE2 was introduced so that the destination address is independent of the exact state of the deploying address. The CREATE2 opcode may only be used by smart contracts that create other smart contracts (like factory contracts).

How is the contract bytecode created?
When a contract is deployed, the EVM executes the init code of the contract, which is an initialization script that runs during contract deployment. It includes the constructor logic and initializes the state of the contract.
After the constructor is successfully executed, the init code is discarded and the runtime bytecode of the contract is stored immutably on the chain. Any time you interact with a smart contract, you’re interacting with that contract’s runtime bytecode.
Constructor arguments are parameters passed into the constructor within a contract’s init code. These arguments help initialize a contract's state, and are typically used to set storage variables, such as the deployer address or the contract’s name. In some cases, the constructor may set immutable variables, which can be inlined into the runtime bytecode of the contract. As a result, child contracts may have different runtime bytecodes if the constructor was passed different immutable values.
To summarize, here are the sequence of events when a child contract is deployed via a factory:
- The EVM determines the address of the child contract via
CREATEorCREATE2 - The EVM generates the runtime bytecode by executing the init code with any constructor arguments
- The EVM stores the runtime bytecode at the newly created address
Challenges with shadowing factory contracts
Armed with that context, let’s dive into some technical challenges of adding shadow factory support.
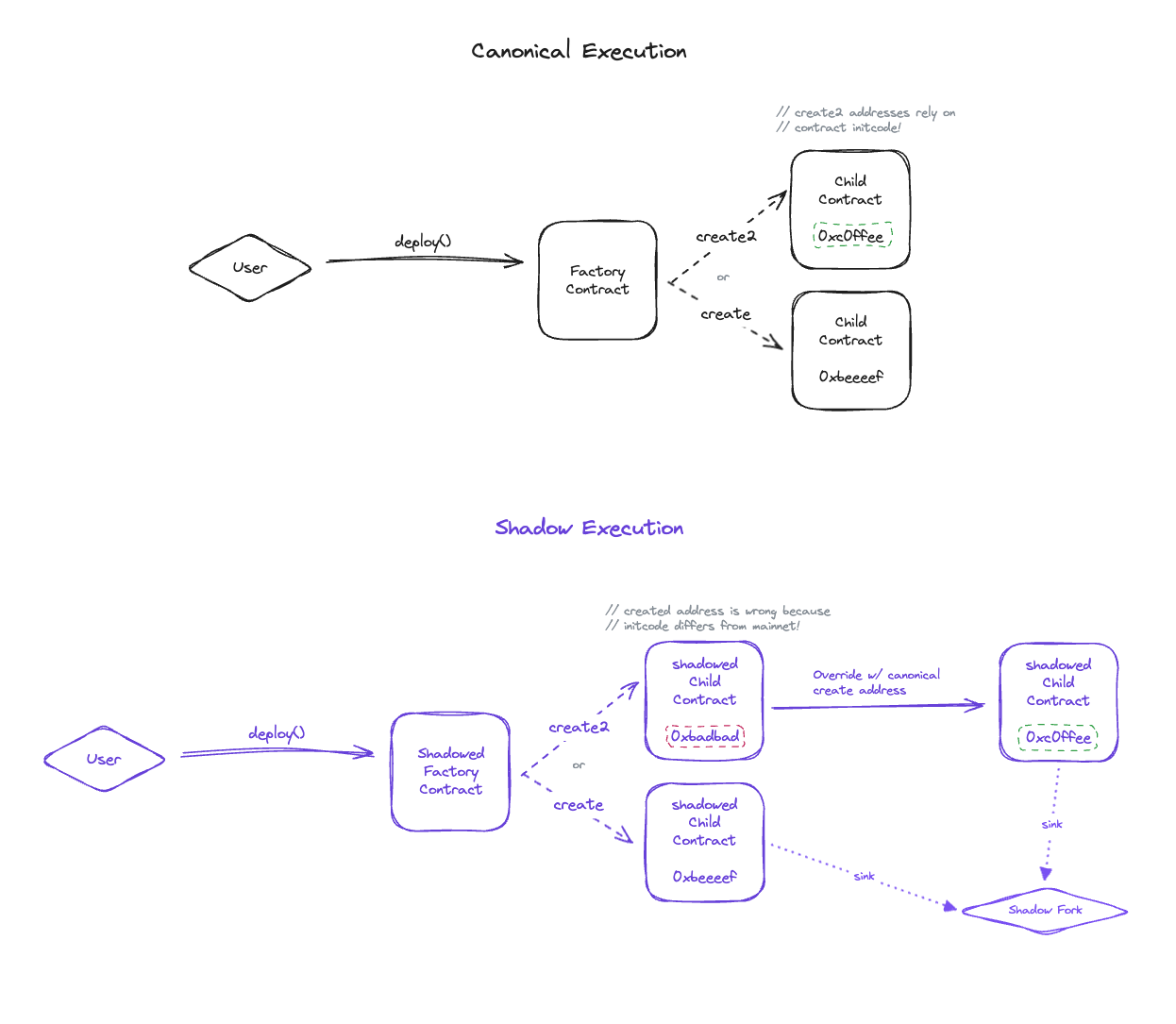
When a shadow contract is deployed onto a shadow fork, we simulate a transaction that executes the shadow init code with the original constructor arguments, and then store the resulting shadow runtime bytecode at the original contract’s address. When we execute transactions on a shadow fork, we swap out the original runtime bytecode with the shadow runtime bytecode.
Adding native support for shadowing factory contracts introduced several challenges:
- Although all child contracts share the same core functionality, we can’t reuse the same runtime bytecode across children because they may have been created with different constructor parameters that were then inlined as immutable variables.
- When you shadow a regular contract, we only need to simulate a single deploy transaction to generate the shadow runtime bytecode. When you shadow a factory contract, we need to simulate N transactions to generate the shadow runtime bytecode for each child.
- The
CREATE2opcode can cause a discrepancy where the child shadow contract address differs from the mainnet address, because the shadow contract has different init code. - Certain contracts, such as Uniswap V3 pools, set
address(this)as an immutable variable. If a contract were to calladdress(this)from the constructor, the computed address would differ from mainnet if the contract was deployed with aCREATE2opcode.
Our approach
We first modified the CREATE and CREATE2 opcodes in a custom revm fork to take an optional address override. When revm calculates the create address of an account, we check if we have an overridden create address, and if so, we bypass the standard create address calculation and use our overridden value.
When a user shadows a factory contract and specifies that their changes should be propagated to all child contracts, a few things happen:
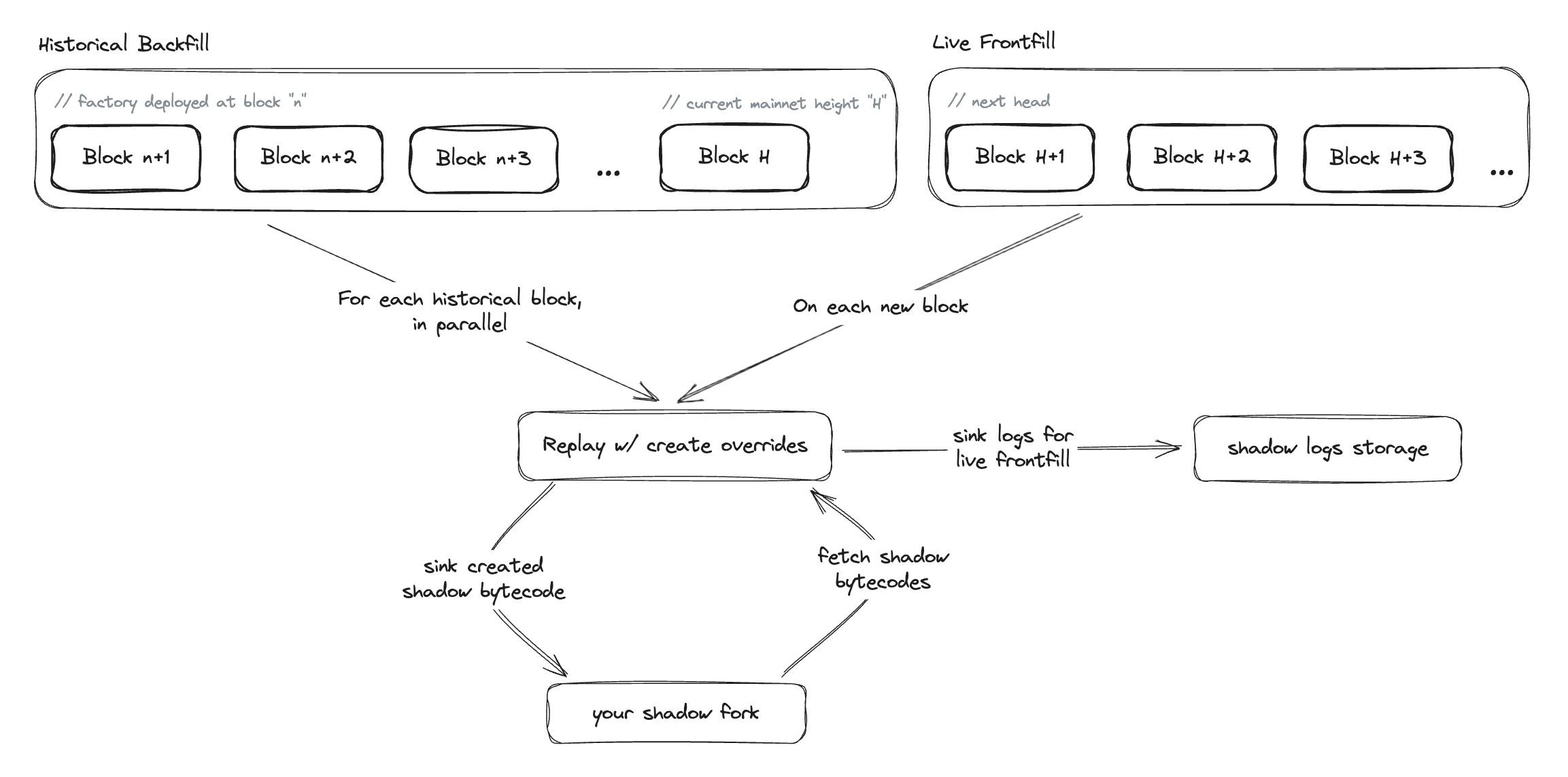
- Shadow kicks off a historical backfill to generate the runtime bytecode for all of the child contracts previously deployed by the factory.
- All deployment transactions of the factory are replayed using our custom revm fork.
- When we replay these deployment transactions, we pass in the original contract’s address as the address override to our custom revm fork. This ensures that the shadow contract address exactly matches the original contract address, and that the resulting runtime bytecode gets initialized with the proper immutable variables.
- We store the resulting runtime bytecode for each child contract.
- Shadow also starts watching for newly deployed child contracts for the shadowed factory at the chain tip. When new contracts are created by the factory, we shadow and save them by roughly following the same process outlined above; replaying the transaction with canonical address override and saving the resulting shadowed child contract’s bytecode to the user’s fork.
Conclusion
Native support for shadowing factory contracts makes it significantly easier to get deeper data coverage across the entire history of the chain.
With factory support, you are able to make one set of changes to a factory contract, and propagate those changes across all of the child contracts it has ever deployed – instead of tediously shadowing i.e. all 300K+ Uniswap V2 pool contracts.
Building this powerful functionality required solving some fun problems related to the EVM and shadow fork execution. We’re excited to see what you do with it!
If this technical dive nerdsniped you, please reach out to us at gm@shadow.xyz. Let's work together to drive forward the future of onchain data.