
Pendle improves trade routing by 34% with Shadow


Pendle Finance is a DeFi protocol with over $6 billion in TVL that allows users to tokenize and trade future yields.
Over the past few months, Pendle has been using Shadow to get extra data out of their router contract that has enabled them to make data-driven decisions and quickly iterate on their trade routing algorithm for the Pendle AMM. These changes have been shipped to production and have resulted in lower transaction fees for 34% of swappers during periods of high activity.

Background
Pendle’s AMM is designed specifically for trading yield, and users trade exact amounts of Principal Tokens (PT) in or out of the pool, against some variable amount of a wrapped yield-bearing token.
When a user makes a swap on Pendle, their router contract runs an approximation algorithm as binary search, to determine how many tokens the user should pay or receive on the variable side of the trade. While running the entire binary search algorithm entirely onchain is technically possible, it would be far too gas intensive.
So instead, the team has developed a clever system where the search range is first narrowed, and then posted onchain. And simultaneously, an offchain algorithm runs to generate a result over a fuller search range. The onchain result is compared against a boundary accepted range; if it is within range, then the result is accepted. If not, then a binary search is run onchain on the narrowed range.
Long Vuong Hoang, Pendle’s Head of Engineering, has been dying to know how efficient this algorithm is.
Interview
How did you use Shadow to understand existing behavior?
The first question I asked was, “what is the distribution of onchain algorithm runs that we are seeing?”. I was able to easily add shadow events to our router contract using Shadow's browser IDE, export the decoded data with their data export feature, and generate a chart to visualize this.
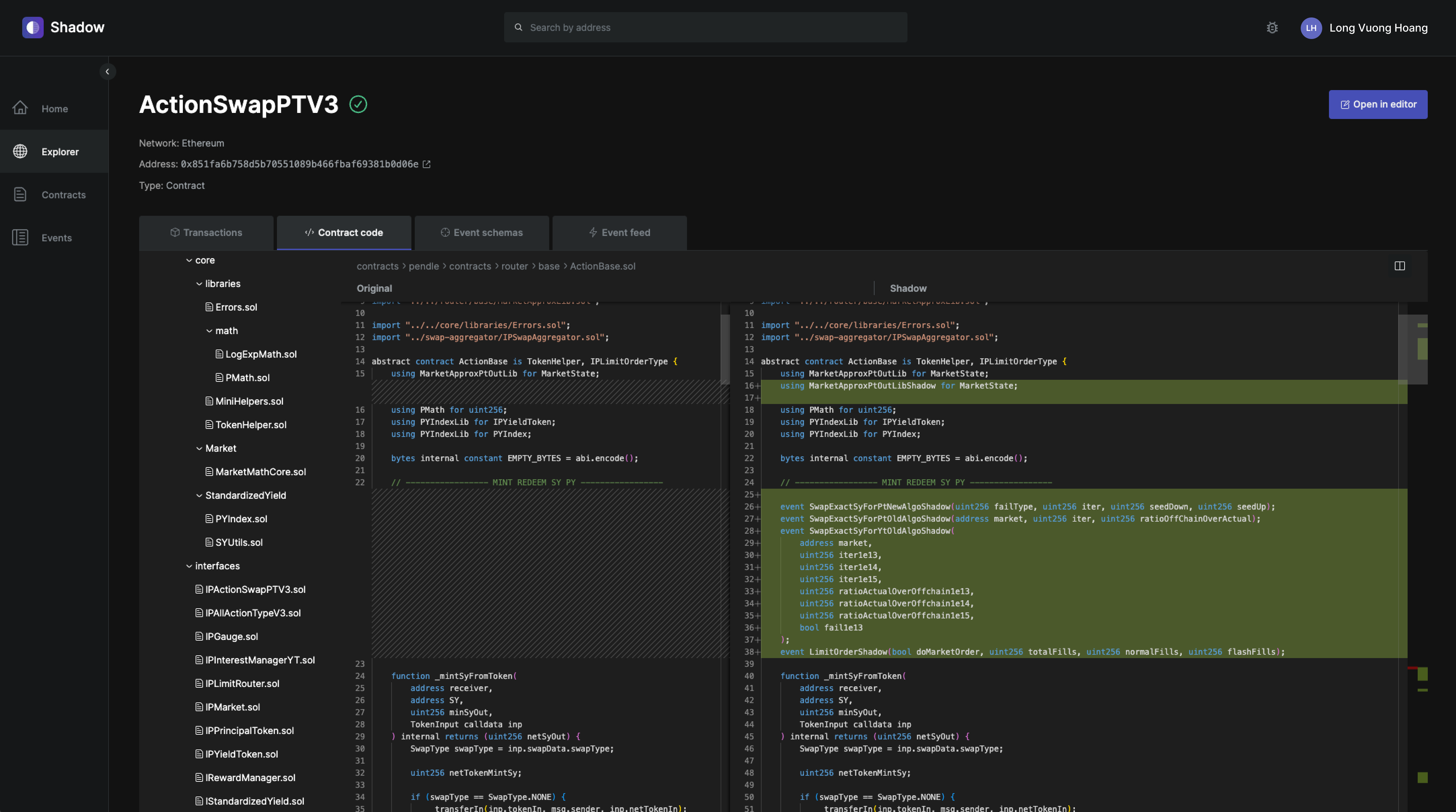
We were able to learn that during periods of normal activity, about 10% of transactions resulted in additional runs. And during periods of high activity, 34% of swaps resulted in the onchain algorithm to run more times than we expected. This caused users to pay more gas for the transaction, with about 50% of those users paying upwards of 80,000 in extra gas for the transaction.
After we had these initial results, then I wanted to know, “were these extra runs to account for positive slippage or negative slippage?”. The algorithm re-runs because the user deserves to get more, or deserves to get less based on realtime market conditions. And so were able to break the results out by positive slippage or negative slippage, and see the run count breakdown for each. The data we got answered an important question: “how many runs does it take to meet our slippage requirements?”.
We have a lower limit for negative slippage, and a higher limit for positive slippage. Additionally, there's a parameter that defines the boundary of how close we need to get to these slippage limits in order for the trade to get executed. The smaller the parameter value, the better the user’s price execution will be, but there's a tradeoff because it’s also more likely that the onchain algorithm will need to run multiple times, and the user will end up paying more in transaction gas fees.
How did you use Shadow to improve the trade routing algorithm?
We wanted to use Shadow’s magic to its maximum. So we asked, “what if we had tweaked this slippage boundary parameter in the past? How would the algorithm have reacted?”. So I increased the parameter value significantly to see how the results would change.
I wanted to do this because as Pendle has gotten more popular, we’ve seen a significant increase in trades at the $150-250 range. And at that size, eating a $30-40 gas fee to improve slippage by a few cents makes no sense. Even on a $10,000 trade, you would save $1 on slippage but pay an additional 200,000 in gas (~$30). But at large trade sizes, improving price slippage becomes more important and gas becomes less of a concern.
So what if instead of having a single slippage parameter for all trades, we could tweak the search range for negative and positive slippage, and configure a dynamic parameter based on trade size?
Shadow allowed us to experiment with this and get the results we needed quickly. We designed an algorithm where there is an epsilon, based on the value that the user is trading. We were able to iterate on this very quickly, make a decision, and launch it confidently into production having backtested 10s of thousands of transactions.

How would you have tried to do this before Shadow?
Before, how we would approach something like this, is we would just go by experience. We’d change something, manually replay a few dozen transactions, and then launch it into production. We’d then monitor it for a bit and replay another few dozen transactions. But that’s a much smaller sample size, and this type of work is very boring and time consuming. You have to fork and replace the bytecode at every single block, change the block, wait for the runs, etc. We were certainly not able to explore the idea anywhere as quickly. Shadow enabled very rapid iteration speed, which helped a lot. It doesn’t break your workflow – you can run, see the results, and run again.
We were able to do much much more than that with Shadow. Even now, I'm not quite sure how I would go about replaying 10,000 transactions without Shadow. We would have to run a custom node or something, because we definitely wouldn’t simulate it one by one.
How do you think about what to log as a shadow event vs mainnet event?
When you deploy events, they’re immutable – you tend to try to think of all the scenarios. But it's only when a system actually runs, that you really get an idea of all the data that you want. Only when a system actually runs, do you start to observe everything and actually start to ask questions. But by then, it’s too late to add regular events.
Of course you can emit a bunch of events in the main contracts if gas wasn’t as much of a concern, like on an L2. But in my experience, no amount of data is ever enough. After you get some data, you decide to get more data. I did a lot of iterations on the shadow events that we ended up using to make the production decision. I emitted it, analyzed results, figured out what else I was missing, and then iterated on it and analyzed it again. I went through those steps many times.
And emitting the event will lie on the main contract execution path. So let’s say you call some function and it turns out to revert or something, then that’s a huge issue. So you cannot just emit all the events you wish, because it needs to go through audits. It doesn’t make sense to upgrade contracts on a daily or weekly basis just to emit events we want. So even if gas was not a concern, there are a lot of events that I would not put on the actual contract.
What has been your experience overall with Shadow?
We've been absolutely loving using the platform, and working with the Shadow team. They have been super responsive to feedback, and have already shipped a number of features and performance improvements that we’ve requested.
Fundamentally, Shadow is technology that unlocks new things. Previously, the effort for doing anything like this was so large that we didn’t really consider doing it. Now, our team can make a ton of progress in just one day.
We've been really happy with Shadow's platform, and are very excited to continue exploring what we can do with it. There are so many ideas that we’ve had in the past, that are now possible to execute on because we can get additional data. We feel like we’re just starting to scratch the surface of use cases for shadow events to become even more data-driven as a team.
Conclusion
The engineering team at Pendle Finance leverage Shadow to:
- Generate extra data on their smart contracts that allowed them to better understand how their systems behave under various conditions
- Iterate quickly and make data-driven decisions on product improvements that were shipped into production
- Achieved lower transaction fees for 34% of swappers on the Pendle AMM during periods of high activity
If you're interested in learning more about how your team can use Shadow to become more data-driven and move faster, reach out to us gm@shadow.xyz.
Thank you to Long and the rest of the Pendle team for collaborating on this case study and their continued partnership!